Data Source Heterogeneity and its Influence on Phenotyping in Distributed Data Networks
Video
Team Information
Team Members
Anna Ostropolets, PhD Candidate, Department of Biomedical Informatics, CUIMC
Faculty Advisor: George Hripcsak, Vivian Beaumont Allen Professor of Biomedical Informatics and Department Chair, Vagelos College of Physicians and Surgeons
Abstract
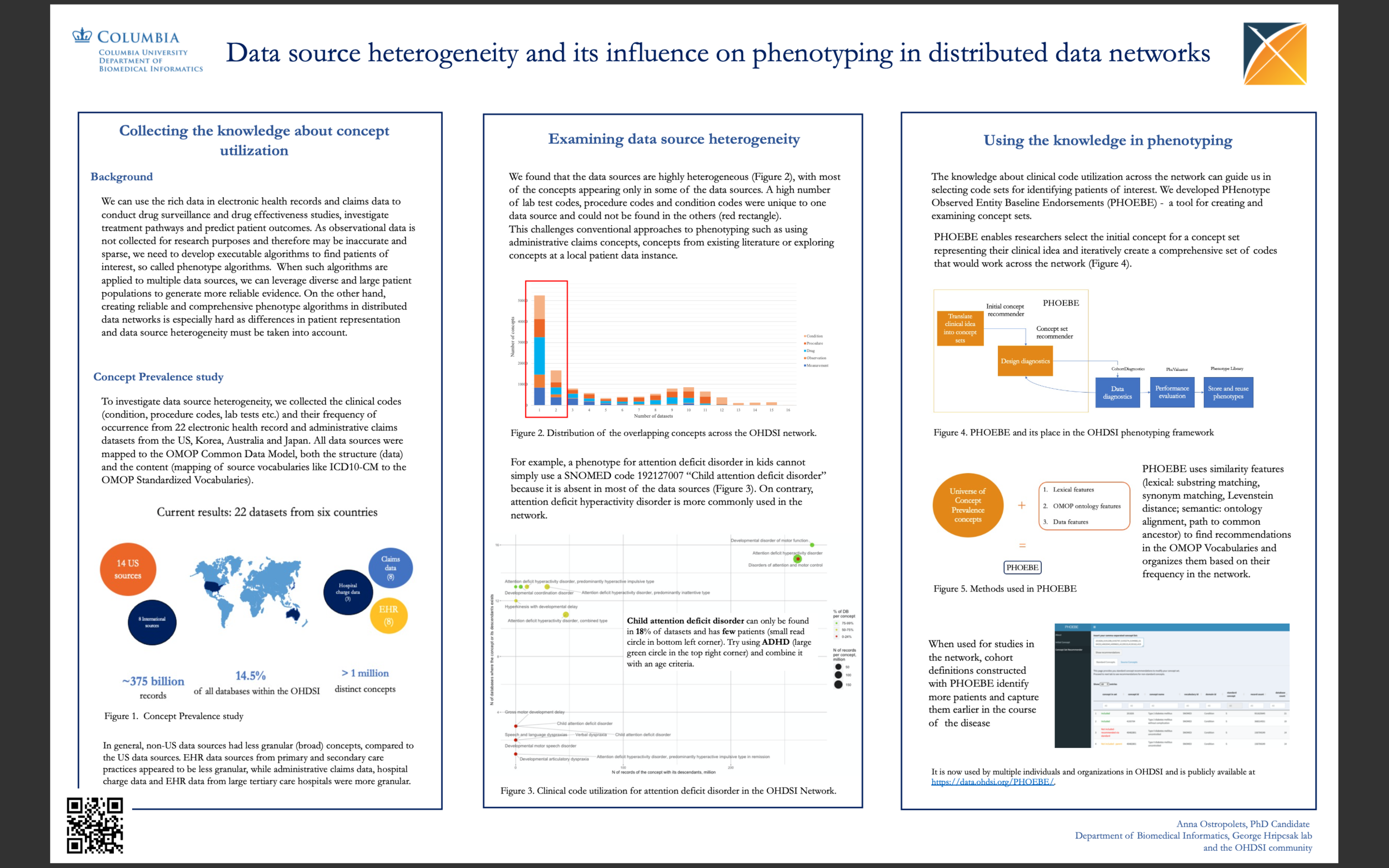
We can use the rich data in electronic health records and claims data to conduct drug surveillance and drug effectiveness studies, investigate treatment pathways and predict patient outcomes. As observational data is not collected for research purposes and therefore may be inaccurate and sparse, we need to develop executable algorithms to find patients of interest, so called phenotype algorithms. When such algorithms are applied to multiple data sources, we can leverage diverse and large patient populations to generate more reliable evidence. On the other hand, creating reliable and comprehensive phenotype algorithms in distributed data networks is especially hard as differences in patient representation and data source heterogeneity must be taken into account.
This poster presents our work on investigating data source heterogeneity and code utilization and how they impact patient phenotyping. We collected more than one million concepts and their frequencies from 22 EHR and claims data sources across 6 countries and found that the data sources are highly heterogeneous, with a high number of lab test codes, procedure codes, and condition codes appearing only in one data source. Granularity of data sources varied greatly as well. Using code utilization data along with lexical and semantic similarity features, we created PHOEBE – a publicly available recommender system that facilitates code selection for phenotyping. When used for studies in the network, cohort definitions constructed with PHOEBE identify more patients and capture them earlier in the course of the disease.
Team Lead Contact
Anna Ostropolets: ao2671@cumc.columbia.edu